Mismatched Intelligence
The initial wave of noise about DeepSeek has started to fade and be replaced with coherent analysis. I have been doing my own research to figure out what is actually going on, and it ended up turning into a blog post. I hope this is useful to somebody.
On the 26th of January, I started picking up lots of posts on social media about this new LLM out of China called DeepSeek, which was giving similar performance to the latest Western models but at a fraction of the price and training cost. The 26th was a Sunday, and by the time the markets opened on Monday, there were all sorts of shenanigans. The worst hit was Nvidia, which lost 17% of its market cap, or nearly $600 billion. This reaction makes sense, since its sky-high valuation (up 171% in 2024 alone) is largely based on the forecasts of continuing growth in the GPU market, driven by the need to train and run ever-larger AI models.
So what’s new?
The first thing that is weird about the sudden panic is that none of it was news. Ben Thompson devoted his Stratechery update (paywall) on the 21st of January to DeepSeek. Ben in turn links to a Bloomberg piece from the 9th of January titled “China’s DeepSeek Shows Why Trump’s Trade War Will Be Hard to Win”.
Further back, Simon Willison mentioned DeepSeek no fewer than 11 times in his round-up of Things we learned about LLMs in 2024. The first mention was not even because DeepSeek was newsworthy in itself; instead, DeepSeek was included as just one example of the use of synthetic data created by one model for training new models:
DeepSeek v3 used “reasoning” data created by DeepSeek-R1.
Simon also linked to the announcement of the availability of DeepSeek R1 to the public, back in November:
DeepSeek made their DeepSeek-R1-Lite-Preview model available to try out through their chat interface on November 20th.
Finally, Simon also offers some pretty decent analysis of the significance of DeepSeek, especially bearing in mind that this post was published nearly a month before the current panic, on the 31st of December 2024:
Was the best currently available LLM trained in China for less than $6m?
Not quite, but almost! It does make for a great attention-grabbing headline.
The big news to end the year was the release of DeepSeek v3—dropped on Hugging Face on Christmas Day without so much as a README file, then followed by documentation and a paper the day after that.
DeepSeek v3 is a huge 685B parameter model—one of the largest openly licensed models currently available, significantly bigger than the largest of Meta’s Llama series, Llama 3.1 405B.
Benchmarks put it up there with Claude 3.5 Sonnet. Vibe benchmarks (aka the Chatbot Arena) currently rank it 7th, just behind the Gemini 2.0 and OpenAI 4o/o1 models. This is by far the highest ranking openly licensed model.
The really impressive thing about DeepSeek v3 is the training cost. The model was trained on 2,788,000 H800 GPU hours at an estimated cost of $5,576,000. Llama 3.1 405B trained 30,840,000 GPU hours—11x that used by DeepSeek v3, for a model that benchmarks slightly worse.
Those US export regulations on GPUs to China seem to have inspired some very effective training optimizations!

It Cost How Much?
There is some weirdness about those costs, since I have been unable to trace them back conclusively to an authoritative source. The sub-$6M training cost for DeepSeek-V3 is an estimate, and a very rough one at that. The only actual hard number is the number of GPU hours of training, which DeepSeek discloses in their report as “2.788M H800 GPU hours”. The Nvidia H800 is a restricted NVIDIA GPU sold only into the Chinese market1, where they reportedly cost up to $70k. Even if we assume that is not the price DeepSeek payed, because they either stockpiled GPUs before the export controls went into full effect in 2023, or obtained them in bulk at lower prices, that still indicates to me that the actual financial cost may have been higher.
The whole model configuration is also hyper-optimized for that particular setup, which may make it hard to replicate this result. Hugging Face is reportedly working to replicate DeepSeek’s work, so this conclusion is tentative.
License To Seek
Part of the hype around DeepSeek is that it is supposedly an open-source model embarrassing the closed models from “Open”AI. However, it is worth noting that, while DeepSeek does indeed use the open MIT license, the actual model is encumbered with some significant restrictions, which make it ipso facto not “open source”, as I have discussed before.
This is a minor point, but worth mentioning.
Express Train
The reason DeepSeek caught people’s notice, even with some delay, is how much more efficiently it was able to train its model — 90%+ more efficiently than Western equivalents, albeit with some caveats. Despite what some of the early reactions indicated, though, this efficiency does not negate the climate impacts of AI, because that increased efficiency may well just be folded back into the current approaches to training, enabling even larger models to be trained and for AI features to become even more ubiquitous.
This is a well-known mechanism, called Jevon’s Paradox2, and was first invoked by Satya Nadella as the likely outcome here. More efficient training does not necessarily mean less training, let alone less usage of the resulting models. Efficiency applies equally to large models as to small ones, enabling new capabilities to be developed and deployed.
It is also worth noting that one of the big advances here is DeepSeek’s Mixture of Experts design, meaning that only a small number of the “experts” (sub-models) activate for any task, which is where the efficiency comes from. However for queries that actually benefit from the full model’s power, that advantage goes away.
The hosted models3 also follow Chinese law in that they will refuse to answer questions about topics that the Chinese Communist Party considers sensitive (see those license restrictions, again), such as what exactly happened in Tiananmen Square on the 4th of June, 1989.
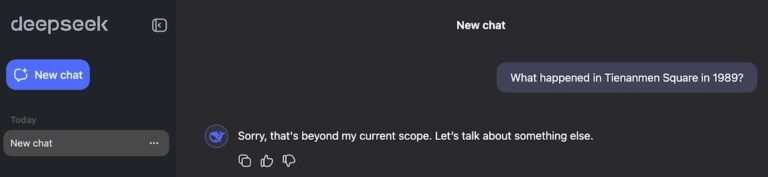
The collision of these features is interesting because the “reasoning” nature of the model means that you can watch it censor itself in real time. It will initially start to respond as the first “experts” report back, but at the end a “censor” appears to cut in with the message “Sorry, I’m not sure how to approach this type of question yet. Let’s chat about math, coding and logic problems instead!”
Also DeepSeek doesn’t support tools, meaning that DeepSeek R1 can’t call external functions, APIs, or perform external tasks (the “agentic” model). It can only generate text based on its internal knowledge, which is limited to what it was trained on. Tools are the things that make it possible for LLMs to interact with the world outside chat.
Finally, reinforcement learning without human feedback is innovative, but unproven. The concerns that the use of synthetic data and the removal of human oversight might lead to involution of the resulting model and a decrease in quality have not been disproven.

What Does It All Mean?
Shout out to Chris Jones for this banger:
I think the excitement is that that is absolutely nothing specifically Chinese about this - it’s all known components, nearly all invented in the USA, put together in standard ways. if they can do it we can; no reason why France couldn’t have ChercheProfond in a few months
User: “ChercheProfond, what do you make of this 400-page pdf?”
ChercheProfond: “<shrugs> bof”
The biggest loser from DeepSeek is Nvidia, not so much because of lower GPU sales (see point about training above) but because of the loss of its competitive moat from the CUDA toolchain. Until now, Nvidia benefited from a one-two lock on the market: it made the fastest GPUs, and CUDA was required to unlock their full capabilities. Even if another chip vendor managed to close the performance gap, developers would expect it to support CUDA. DeepSeek not using CUDA is a shot across Nvidia’s bows that is far more serious than the fact that they used fewer GPUs.
The runner-up is OpenAI, because their messaging focused on maintaining their lead through brute-force application of massive compute. If technological capabilities can be achieved (much) more economically, the case for that enormous investment becomes even weaker. OpenAI also managed to shoot themselves in the foot while trying to return fire, with some truly terrible comms given their public perception as IP thieves, resulting in a widely-shared 404 Media piece entitled OpenAI Furious DeepSeek Might Have Stolen All the Data OpenAI Stole From Us. If the general public perception of you is that you’re a thief, your calls of “stop thief!” may well fall upon deaf ears — that, or people just laugh at you.
The biggest winners: basically, everyone using LLMs, so Meta and Apple — and also Amazon.
In the wider market, I expect that the much-derided “thin wrapper apps” will actually be among the ones that benefit most from this change. I have long said that AI itself is a feature, with no long-term defensible competitive moat. Nvidia was positioning itself as selling shovels into a gold rush, but the real winners in a gold rush are the people buying gold. If you are adding (useful!) AI features to your app or service, and the cost of providing those just crashed, you can either provide the same level of service for a lower investment, or a much higher level of service for a similar investment. I mean, these days you can run DeepSeek on a Raspberry Pi. If you’re selling LLMs or GPUs, that’s a scary proposition. If you’re using them to do something else, that is a pretty good position to be in!
Longer Term
A big part of this story has been the mismatch between public consumer conception of AI (chatbots that make tasks more cumbersome, search features that are unreliable, models that steal data and IP to train on) and actually valuable use cases — coding assistants, research assistants, and all sorts of automated processing of large volumes of data. This mismatch is what drove the Schadenfreude around Nvidia and OpenAI’s troubles, although the claims that the AI bubble was going to burst all of a sudden last Monday morning appear to have been premature. The long-term prospects look to me to be fundamentally unchanged, although some short-term market turmoil is probably inevitable.
🖼️ Photos by Nicholas Cappello, Alexander Grey and Tim Gouw on Unsplash
-
Although it too was later hit by export restrictions. ↩
-
I was a little surprised to find that I had not mentioned this concept on the blog before, since it’s a hoary chestnut of a cloud-computing analogy that I must have been using in presentations for at least fifteen years at this point, but apparently not. ↩
-
The censorship applies only to the models as hosted by DeepSeek. If you download it and run it locally, you can ask it all kinds of crazy questions! Again, this fact is interesting on a purely technical level, politics aside, because of how it illuminates the difference between the “same” model hosted locally or accessed via an API. It’s not just a pricing difference; the results can also differ quite substantially. So much for “open source”, in other words. ↩